Pythonで浅いリストを平坦化する
リストの内包表記を使ってイテラブルのリストを平坦化する簡単な方法はありますか、それとも失敗した場合、パフォーマンスと読みやすさのバランスをとりながら、このような浅いリストを平坦化する最善の方法は何でしょうか。
このようなリストを入れ子にされたリスト内包表記でフラット化しようとしました。
[image for image in menuitem for menuitem in list_of_menuitems]
name 'menuitem' is not definedなので、私はそこでNameErrorの種類の問題に悩みます。グーグルしてスタックオーバーフローを見回した後、私はreduceステートメントで望ましい結果を得ました:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
しかし、xはDjangoのQuerySetオブジェクトなので、list(x)を呼び出す必要があるので、このメソッドはかなり読みにくいです。
結論:
この質問に貢献してくれた皆さんに感謝します。これが私が学んだことの要約です。他の人がこれらの所見を追加または修正したい場合に備えて、私もこれをコミュニティWikiにしています。
私の最初のreduceステートメントは冗長であり、このように書かれているほうが良いでしょう。
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
これはネストしたリストの内包表記の正しい構文です(素晴らしい要約 dF !)。
>>> [image for mi in list_of_menuitems for image in mi]
しかし、これらのメソッドはどちらもitertools.chainを使うほど効率的ではありません。
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
@cdaryaryノートにもあるように、chain.from_iterableを使って*演算子の魔法を避けるのがおそらくより良いスタイルです:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
単純化されたバージョンのデータ構造を反復処理したいだけで、インデックス可能なシーケンスが不要な場合は、 itertools.chain and company を検討してください。
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
それは反復可能なものであれば何でも動作します。それにはDjangoの反復可能なQuerySetsが含まれるはずです。
編集:これはおそらくreduceと同じくらい良いです、なぜならreduceは拡張されているリストに項目をコピーするのと同じオーバーヘッドがあるからです。 chainは、最後にlist(chain)を実行した場合にのみ、この(同じ)オーバーヘッドを招きます。
Meta-Edit:実際には、質問で提案されている解決策よりもオーバーヘッドが少なくなります。 。
編集:--- JF Sebastianによるitertools.chain.from_iterableは解凍を避け、*マジックを避けるためにそれを使うべきですが timeit app はごくわずかなパフォーマンスの違いを示しています。
あなたはほとんどそれを持っています! ネストしたリストの内包表記を行う方法 は、通常のネストしたforステートメントの場合と同じ順序でforステートメントを配置することです。
したがって、これ
for inner_list in outer_list:
for item in inner_list:
...
に対応
[... for inner_list in outer_list for item in inner_list]
あなたが望んでいるのは
[image for menuitem in list_of_menuitems for image in menuitem]
@ S.Lott :あなたは私にtimeitアプリを書くように促しました。
私はそれがまたパーティションの数(コンテナリスト内のイテレータの数)に基づいて変わるだろうと考えました - あなたのコメントは30個の項目があったパーティションの数について言及していませんでした。このプロットは、さまざまなパーティション数で、実行ごとに1000項目を平坦化しています。アイテムはパーティション間で均等に分配されます。
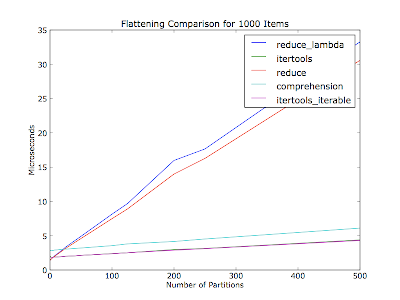
コード(Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __== '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
編集:コミュニティウィキにすることにしました。
注:METHODSはおそらくデコレータで累積されるべきですが、私は人々がこの方法を読むのがより簡単であると思います。
sum(list_of_lists, [])はそれを平らにします。
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
この解決方法は任意の入れ子の深さに対して機能します - 他の解決方法のいくつか(すべて?)が以下に制限される「リストのリスト」の深さだけではありません。
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
それは任意の深さの入れ子を可能にする再帰です - もちろんあなたが最大再帰深さに達するまで...
Python 2.6では、 chain.from_iterable() を使います。
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
中間リストの作成を避けます。
パフォーマンス結果改訂しました。
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
私は30項目の2レベルのリストを1000回平坦化しました
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
減らすことは常に悪い選択です。
operator.addと混同しているようです! 2つのリストを一緒に追加するとき、それに対する正しい用語は追加ではなくconcatです。 operator.concatはあなたが使う必要があるものです。
あなたが機能的と考えているなら、これはこれと同じくらい簡単です::
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
あなたはreduceがシーケンスタイプを尊重しているのを見るので、あなたがTupleを供給するとき、あなたはTupleを取り戻します。リストで試してみましょう::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
ああ、あなたはリストを取り戻します。
パフォーマンスはどうですか::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterableはかなり速いです!しかし、concatで減らすのは比較ではありません。
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
私の頭の上では、ラムダを排除することができます。
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
あるいはlist-compをすでに持っているので、地図を削除することさえできます。
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
これをリストの合計として表現することもできます。
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
これはリスト内包表記を使用した正しい解決策です(これらは質問の後ろにあります)。
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
あなたの場合はそれでしょう
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
あるいはjoinを使って言うこともできます
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
どちらの場合も、問題はforループのネストでした。
このバージョンはジェネレータです。リストが必要な場合は弱めてください。
def list_or_Tuple(l):
return isinstance(l,(list,Tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/Tuple
def flatten(seq,predicate=list_or_Tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
条件を満たすものを平坦化したい場合は、述語を追加できます。
Pythonクックブックから撮影
私の経験からすると、リストのリストを平坦化する最も効率的な方法は次のとおりです。
flat_list = []
map(flat_list.extend, list_of_list)
他の提案された方法とのいくつかのtimeitの比較:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
現在は、より長いサブリストを処理するときに効率の向上が見られます。
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
そして、このメソッドはあらゆる反復オブジェクトに対しても機能します。
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
平らにしてみましたか? matplotlib.cbook.flatten(seq、scalarp =) から?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
UPDATEこれは私に別の考えを与えました:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
再帰的になるとそれがどれほど効果的であるかをテストするために:どれほど深く?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
"flatten"がmatploblib.cbookで使用されているので、歩留まりジェネレータと高速な結果が必要でない限り、私は長い間matploblibではなくこれを使用するつもりです。
これは速いです。
- そしてここにコードがあります
:
typ=(list,Tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
これはcollectons.Iterableを使用して複数レベルのリストに対して動作するバージョンです。
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
pylabはflattenを提供します: numpy flattenへのリンク
内蔵のシンプルなワンライナーをお探しの場合は、次のものを使用できます。
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
戻る
[1, 2, 3, 4, 5, 6]
どうですか?
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
しかし、Guidoは読みやすさを低下させるため、コードを1行で実行しすぎることをお勧めします。 1行でも複数行でも必要なパフォーマンスを実行しても、パフォーマンスはほとんど向上しません。
反復不可能な要素または深さが2を超える複雑なリストを平坦化する必要がある場合は、次の関数を使用できます。
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
これはlist()関数でリストに変換できるジェネレータオブジェクトを返します。 yield from構文はpython3.3から利用可能であることに注意してください、しかしあなたは代わりに明示的な繰り返しを使うことができます。
例:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
def is_iterable(item):
return isinstance(item, list) or isinstance(item, Tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
テスト:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
リストの各項目が文字列の場合(およびそれらの文字列内の文字列が ''ではなく ""を使用している場合)、正規表現を使用できます(reモジュール)。
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
上記のコードは、in_listを文字列に変換し、regexを使用して引用符内のすべての部分文字列(リストの各項目)を検索し、それらをリストとして吐き出します。
簡単な方法は numpyの連結 を使うことですが、内容をfloatに変換します。
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Python 2または3でこれを実現する最も簡単な方法は、pip install morphを使用して morph ライブラリを使用することです。
コードは次のとおりです。
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
Python 3.4 であなたはできるようになるでしょう:
[*innerlist for innerlist in outer_list]